Riddler Dowries
Nov 1, 2019
Introduction
A small twist on a classic problem is this week's challenge from the Riddler. We're going to tackle an extension of the secretary problem - also known as the Sultan's Dowry problem. This classic puzzle has led to fascinating research in optimal stopping theory, which we will use to determine how effective our Sultan is at choosing a suitor. Let's dive in!
The sultan has asked her vizier to present her with 10 candidates for marriage. The vizier has searched the kingdom for the 10 most desirable partners, but he does not know whom the sultan will prefer. If she saw them all at the same time, she would easily be able to rank them from 1 (the best partner) to 10 (the worst partner). But the vizier can only present the candidates one at a time — very hard to sync everybody’s calendars, even back then — and in a random order. Upon seeing each candidate, the sultan must reject or accept him. If a candidate is rejected, the sultan cannot pick him again. But on seeing each new candidate, she knows exactly where he’d stack up relative to the candidates she has rejected. **If she strategizes, what’s the highest rank she can expect her chosen candidate to have on average?**For example, if she simply accepted the first candidate presented to her, his rank could be anywhere from 1 to 10 with equal probability, averaging to 5.5. Surely she can do better...
As an aside, I recently read Algorithms to Live By, which covered how puzzles like these might be applied to real-life situations as well. It was a fun read discussing how computer science algorithms can help us make better decisions, from folding socks as efficiently as possible to deciding whether to return to our favorite restaurant or try a new one. Highly recommended!
Solution
Thanks to some helpful suggestions, I revised my original answer, in which I used the proven strategy for the original problem, rather than devising a new strategy for the specific problem we are trying to solve this week. In short, if we apply the strategy from the original problem - where we try to choose the single best suitor - the expected result is 3.025. On the other hand, if we devise a new strategy, we can improve the results by roughly half a rank. The following is what I believe to be the ideal strategy and answer. Thanks again for the helpful nudge in the right direction, Riddler Nation twitter!
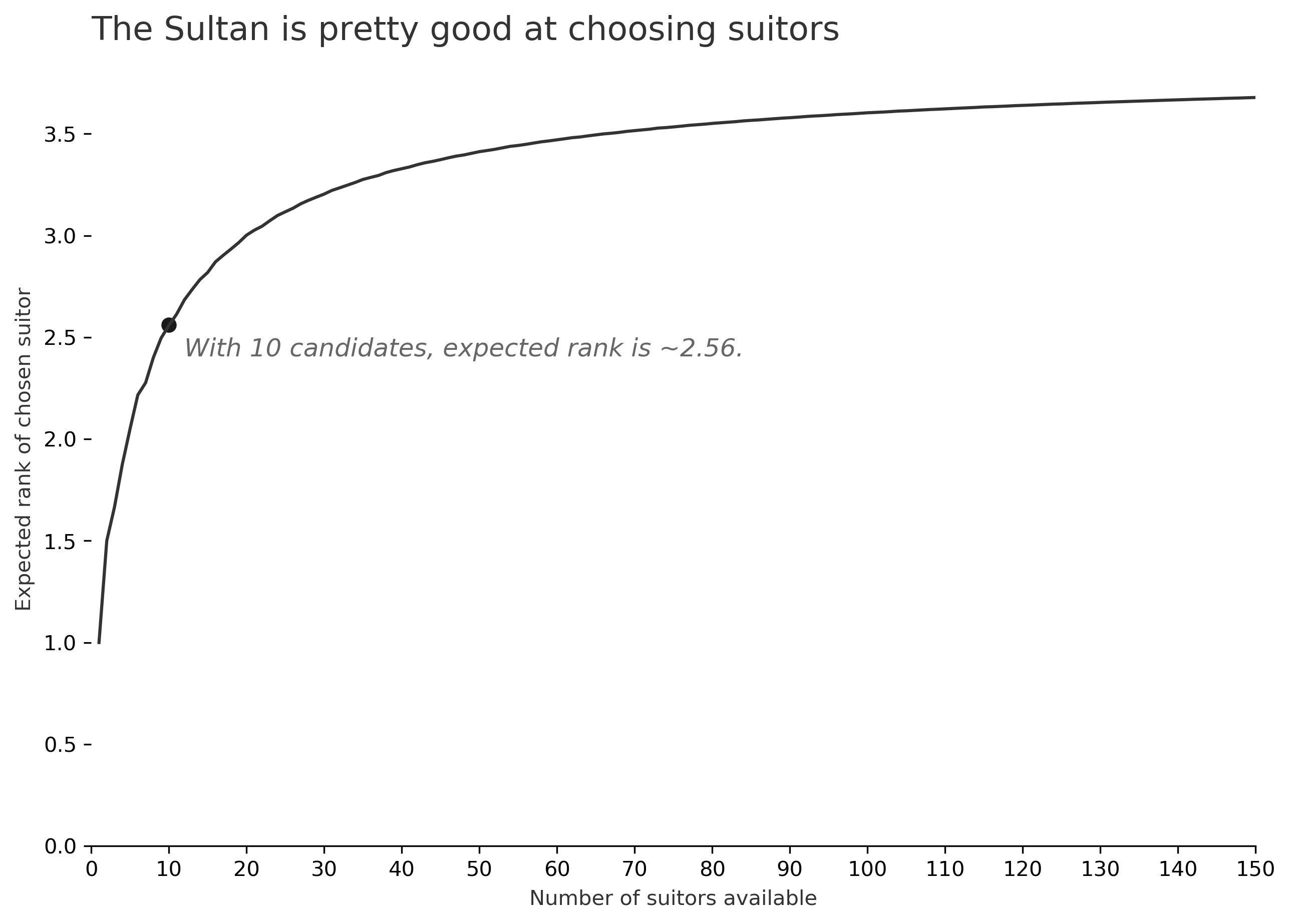
If the Sultan chooses optimally, her suitor will have an average rank of roughly 2.56.
Methodology
We'll solve this problem using Dynamic Programming. I'll create a data structure called "State" that keeps track of everything we know about the world at each point in time. "State" is comprised of three variables.
m- the rank of the current suitor, relative to all suitors we've seen so far. For example, m=2 means we're looking at the second-best suitor we've seen so far.seen- the number of suitors we've seen in total, including the one we're currently considering.N- the total number of suitors available to consider, in our case, the default is 10.
Together, these three variables tell us everything we need to know to make the right decision. To solve the problem, we work backwards, from the last step to the first. We know that we must pick the 10th suitor if we get to that point. We also know the actual rank of the suitor, because we've seen everyone. Therefore, if we have State(m=4, seen=10, N=10), we know the rank we end up with is 4.
If we are viewing the 9th suitor, then we have two options: choose the one we have in front of us, or pass, and gamble that the randomly drawn 10th suitor will be better. Intuitively, we might think that if we're looking at the best suitor we've seen so far: State(m=1, seen=9, N=10), then it makes sense to stop. There's only a 10% chance we would find someone better. But if we're looking at the worst suitor we've seen so far: State(m=9, seen=9, N=10), then it makes sense to pass and take our chances with the next one. When we formalize this process, we calculate the expected value of stopping and the expected value of continuing. At each point in the process, we choose the option that gives us the better (minimum) expected outcome. When we work backwards all the way to the very first suitor we see, we will have the answer we're looking for.
The following code creates the State class by subclassing namedtuple, then adds methods to calculate the stop_value and expected_value of each State. We're interested in the expected value when we start the process, which is State(m=1, seen=1, N=10). Then we call expected_value() to get our answer. It turns out that designing a new strategy from first principles allows us to improve the answer from above, and we get an average expected rank of 2.56.
Furthermore, now that we have a framework with flexible inputs, we can also solve for different values of N - if the Sultan had a pool of 50 applicants, for example. We can plot the expected rank as the value of N changes, and we see a curve that quickly approaches ~3.7, though there has been interesting discussions about the actual limiting behavior of this process.
Full Code
This code is used for the ideal strategy I outline above.
from collections import namedtuple
from functools import lru_cache
import doctest
class State(namedtuple("State", ("m", "seen", "N"))):
"""
Represents the current state of the game. "m" is the rank of
the suitor we are currently considering, relative to the ones
we have seen already. "seen" is the number of candidates we have
already seen, including the one we are currently considering.
"N" is the total number of candidates available.
Parameters
----------
m : int, the relative rank of the current suitor, compared
against the suitors we've seen already. For example,
m=2 means we're viewing the second-best suitor we've seen
up to this point. m <= seen
seen : int, the number of suitors we've seen so far, including
the one we are currently viewing.
N : int, the total number of suitors available
"""
@lru_cache(maxsize=None)
def stop_value(self):
"""
Returns the expected value if we were to choose suitor m
Examples
--------
>>> State(m=3, seen=10, N=10).stop_value()
3.0
>>> State(m=1, seen=9, N=10).stop_value()
1.1
>>> State(m=1, seen=8, N=10).stop_value()
1.2222222222222223
>>> State(m=1, seen=7, N=10).stop_value()
1.3750000000000002
>>> State(m=1, seen=1, N=10).stop_value()
5.500000000000001
"""
if self.seen == self.N:
# if we're viewing the last suitor, stop value is m
return float(self.m)
else:
# otherwise, stop value is the weighted average of seeing
# someone better than m and seeing someone worse than m
better = State(m=self.m+1, seen=self.seen+1, N=self.N).stop_value()
worse = State(m=self.m, seen=self.seen+1, N=self.N).stop_value()
return (
better * self.m + worse * (self.seen - self.m + 1)
) / (self.seen +1)
@lru_cache(maxsize=None)
def expected_value(self):
"""
Returns the expected value of this State, where expected value is
defined as the expected rank of suitor we will end up with if we
make perfect decisions from this point forward.
Examples
--------
>>> State(m=1, seen=9, N=10).expected_value()
1.1
>>> State(m=9, seen=9, N=10).expected_value()
5.5
>>> State(m=1, seen=1, N=10).expected_value()
2.5579365079365086
"""
if self.seen == self.N:
# we must select the last suitor if we get to that point
return float(self.m)
else:
# otherwise, we find ourselves in a future state where seen
# is incremented by one, and we could view any new rank, m
# we then choose the optimal path in those future states
ev = [
State(m=x, seen=self.seen+1, N=self.N).expected_value()
for x in range(1, self.seen+2)
]
ev = sum(ev) / len(ev)
return min(ev, self.stop_value())
if __name__ == '__main__':
doctest.testmod()