Riddler Video Call
May 29, 2020
Introduction
Suppose everyone in the United States wanted to join the same video call? If each of the 330 million participants joins and drops at a random time, how likely is it that at least one person overlaps with everyone else? This problem easily exceeds the limits of a practical simulation, but we'll write some code to develop intuition about the results before attempting to solve it analytically. Here's the full problem text from this week's Riddler.
One Friday morning, suppose everyone in the U.S. (about 330 million people) joins a single Zoom meeting between 8 a.m. and 9 a.m. — to discuss the latest Riddler column, of course. This being a virtual meeting, many people will join late and leave early.In fact, the attendees all follow the same steps in determining when to join and leave the meeting. Each person independently picks two random times between 8 a.m. and 9 a.m. — not rounded to the nearest minute, mind you, but any time within that range. They then join the meeting at the earlier time and leave the meeting at the later time.
What is the probability that at least one attendee is on the call with everyone else (i.e., the attendee’s time on the call overlaps with every other person’s time on the call)?
Extra credit: What is the probability that at least two attendees are on the call with everyone else?
Solution
This is a challenging problem, in part because it exceeds the limits of a simulation that could run in reasonable time, and also because the underlying probability distributions are a little tricky. I'm still working on an analytical solution.
The following image helped me think about the probability distributions involved. Each blue bar represents one participant's time on the call, and we quickly build a stack of participants joining and dropping over time. However, we are especially interested in two participants: the person that leaves the call first, and the person that arrives to the call last.
These two people set the boundary on the minimum overlap time. In order to overlap with everyone, at least one person must join the call before the first person leaves, and must stay on the call until the last person joins. If those two conditions are met, then we're guaranteed to have at least one overlap.
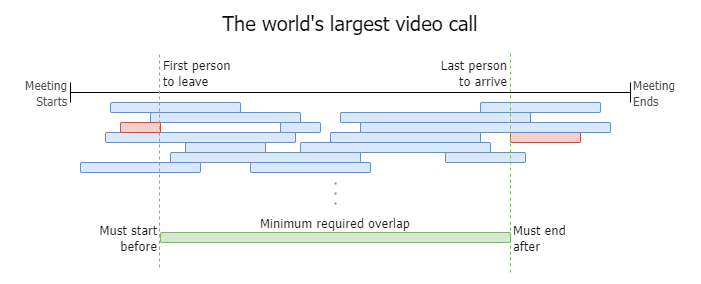
Sample Simulation
While it's impractical to simulate the entire 330-million-person call, I found that simulations with smaller values (100,000 to 50 million or more) consistently yielded values around 66% for at least one overlap, and around 40% for at least two overlaps.
I also had some fun this week playing with dask to run large simulations on my machine. Dask lets you create a "local cluster" on your computer that can parallelize certain operations and run them much faster than you could on a single thread.
The code below creates a dask local cluster, then runs a large batch of simulations that align with the analytical results above.
from dask import array as da
from dask.distributed import Client
# start a local cluster using all CPU threads
client = Client()
def model(trials: int, participants: int):
"""
Returns the number of participants on a call who overlap
with every other participant. This is solved efficiently
using dask arrays for parallel simulations:
1. Generate each person's start and end times. The start
time is the min and the end time is the max.
2. For a group of participants, find the latest start
time and the earliest end time.
3. Identify any participants that have a starting time
before than the earliest end time and an end time
after the latest start time.
Returns
-------
result : an array of the number of participants in each
trial who overlap every other participant.
"""
times = da.random.uniform(size=(trials, participants, 2))
starts = times.min(axis=2)
ends = times.max(axis=2)
latest_start = starts.max(axis=1)
earliest_end = ends.min(axis=1)
# check if any participants arrive before the first person
# leaves and leave after the last person arrives.
cond1 = starts.T < earliest_end
cond2 = ends.T > latest_start
return (cond1 & cond2).sum(axis=0)
# results here is a delayed object. Call `compute() for values
# here we run 1000 trials with 10 million participants
results = model(trials=1000, participants=10000000)
results.compute()